7 Agents, 38 Tasks, $0: Running Claude Code Agent Teams on Local GPUs
Seven agents. Thirty-eight tasks. Three hours of autonomous work. Total API cost: $0.
That's what happened when I pointed a Claude Code multi-agent team at this blog and let it run entirely on local GPU hardware. The typography, the transitions, the polish you're seeing on this site now: all of it came from the setup I'm about to walk through.
No free tier. No credits. Just a proxy that routes Claude Code's API calls to models running on my own machine. Crucially, it allows per-model overrides—for example, you can seamlessly redirect 'opus' requests to Anthropic for high-level planning, while routing all 'sonnet' execution agents to local models for free execution.
The Cost Problem with Agentic Workflows
Single-agent Claude Code sessions are already token-hungry. Ask for a refactor, the model reads a dozen files, thinks through the changes, edits them, runs tests. Maybe 50k tokens. Fine.
Now multiply that by seven agents running in parallel for three hours, each with its own conversation context, tool calls, and inter-agent coordination overhead. At Anthropic's API rates, that bill arrives faster than you'd like.
Ralph loops make it worse in the best possible way. A ralph loop (named after Ralph Wiggum's unfazed persistence) is Claude Code's self-restarting agentic pattern: you define a task and a success condition, and a Stop hook re-injects your prompt after each iteration until the condition is met. It's the right tool for "keep improving this until the tests pass" or "keep refactoring until it's done." It's also a reliable way to burn tokens across dozens of iterations.
The solution is, perhaps, to not use the Anthropic API for sonnet & haiku class models at all.
Claude Model Proxy: The Local API Bridge
claude-model-proxy is a small FastAPI server that sits between Claude Code and Ollama:
Claude Code → proxy (:8082) → Ollama (:11434) → local GPU
It implements the full Anthropic Messages API. Claude Code doesn't know the difference. It sends the same requests it would send to api.anthropic.com, and the proxy translates them to Ollama's format and back, including streaming and tool use.
Setup starts with pulling local models and configuring the proxy. Here's my Ollama model library alongside the .env that maps each Claude tier to a local model:
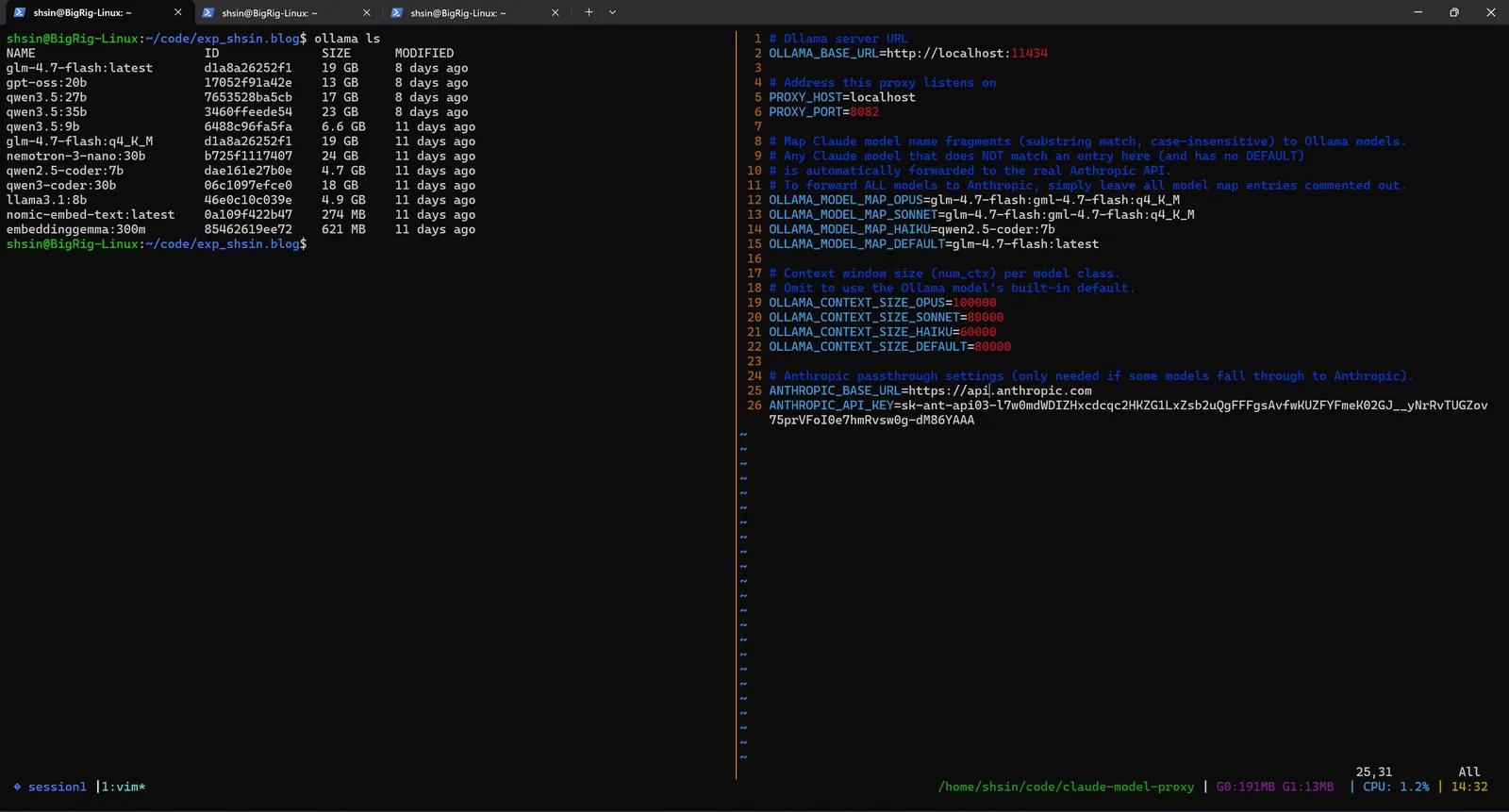
Every Claude model name (Opus, Sonnet, Haiku) gets routed to a local GLM-4.7-Flash (q4_K_M) running on my GPU. Context sizes, timeouts, and Ollama connection details are all configured in the .env file. You can also set any tier to anthropic to pass those requests through to the real API, useful when you want cloud quality for one agent and local speed for the rest.
Kicking It Off
Two environment variables and Claude Code doesn't know it's talking to a local model:
export ANTHROPIC_BASE_URL=http://localhost:8082
export ANTHROPIC_API_KEY=proxy # any non-empty string
claude
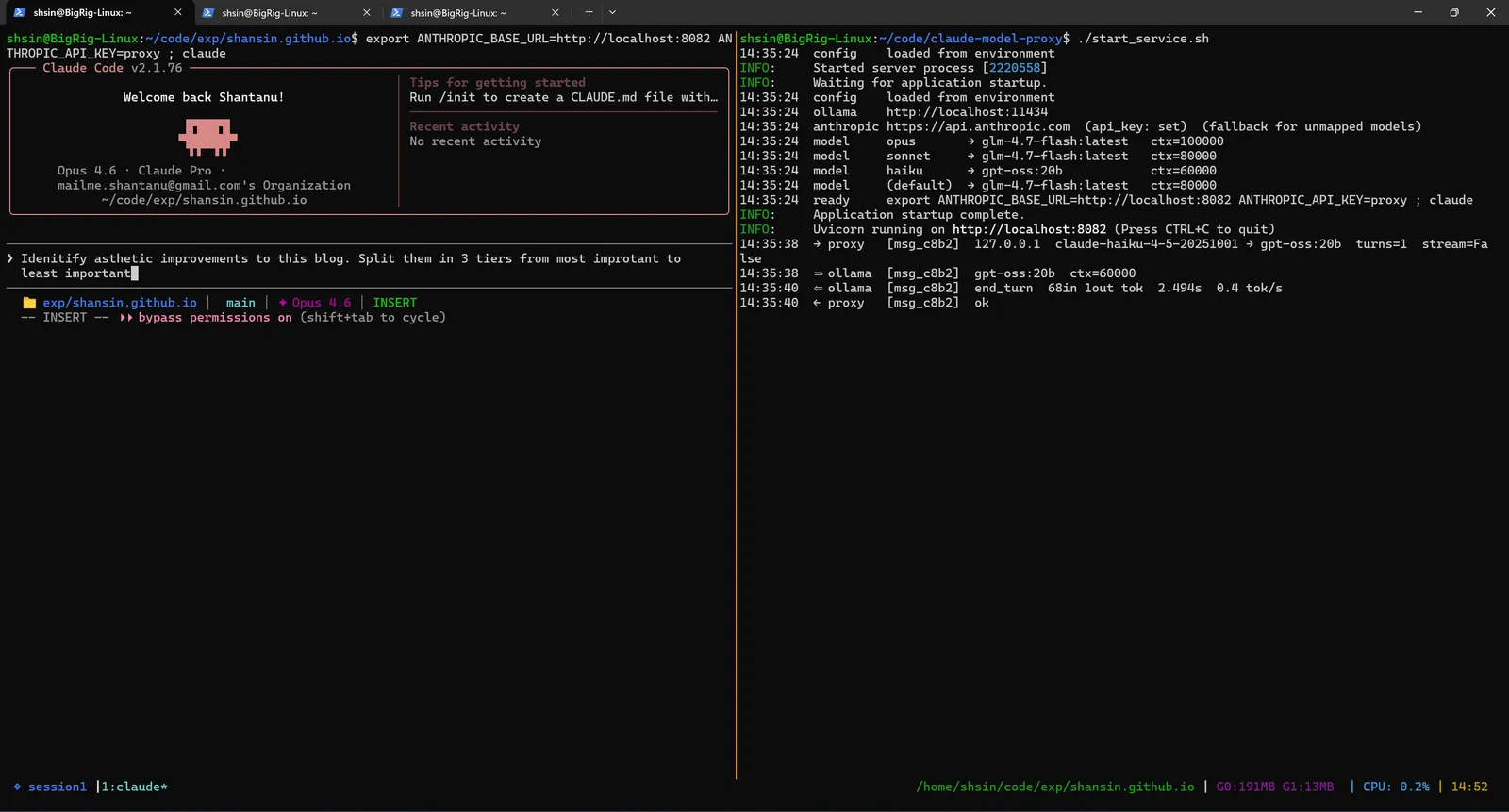
On the left, Claude Code starts normally, same welcome screen, same interface. On the right, the proxy logs confirm every request is being caught and forwarded to the local Ollama instance. Claude Code has no idea it's not talking to Anthropic's servers.
I gave it a simple, open-ended prompt: "Identify aesthetic improvements to this blog. Split them into tiers from most important to least important."
The Lead Agent Plans
Within minutes, the lead agent had scanned the entire codebase, every component, every stylesheet, every layout file, and produced a prioritized improvement plan.
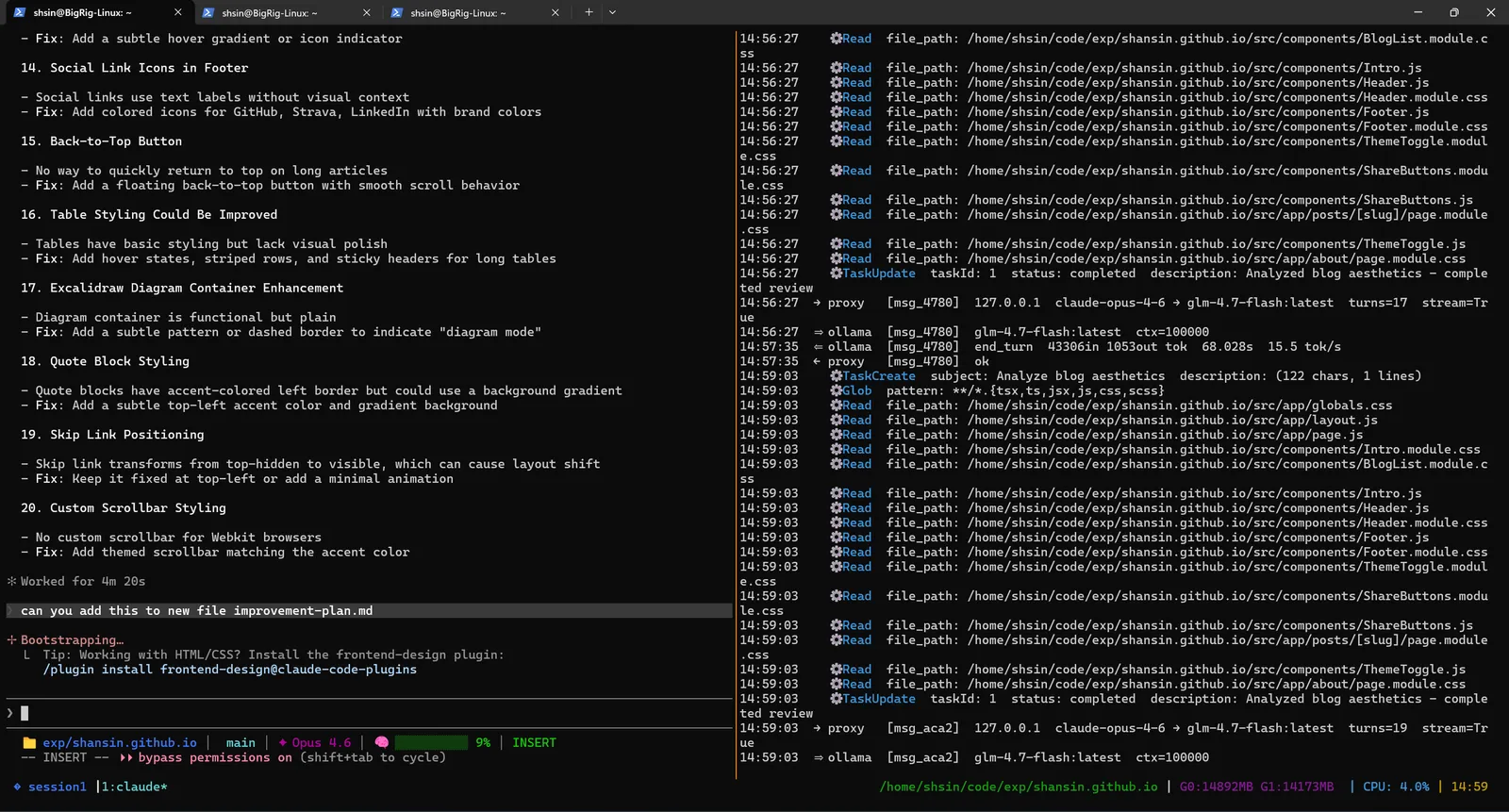
Twenty improvements, categorized by priority. The right pane shows a steady stream of proxy logs: the model reading files, analyzing aesthetics, and reasoning about what matters most. All tokens processed locally.
The agent then structured this into a formal plan document, breaking improvements into tiers:
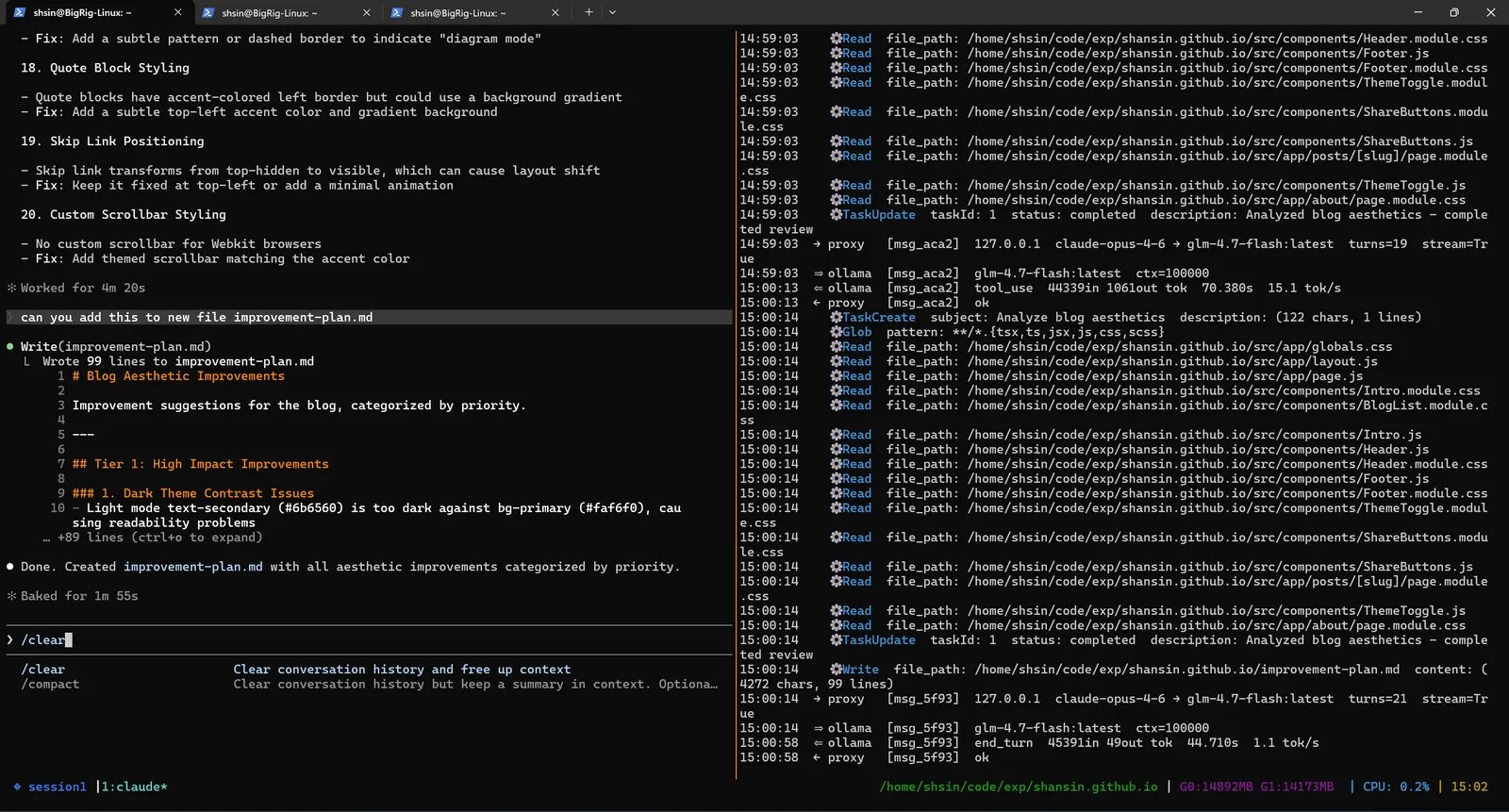
Decomposition: From Plan to Tasks
Next, I asked the agent to read its own improvement plan and turn it into a structured task list, each task scoped small enough to be completed by a junior engineer (or in this case, a local GLM-4.7-Flash model).
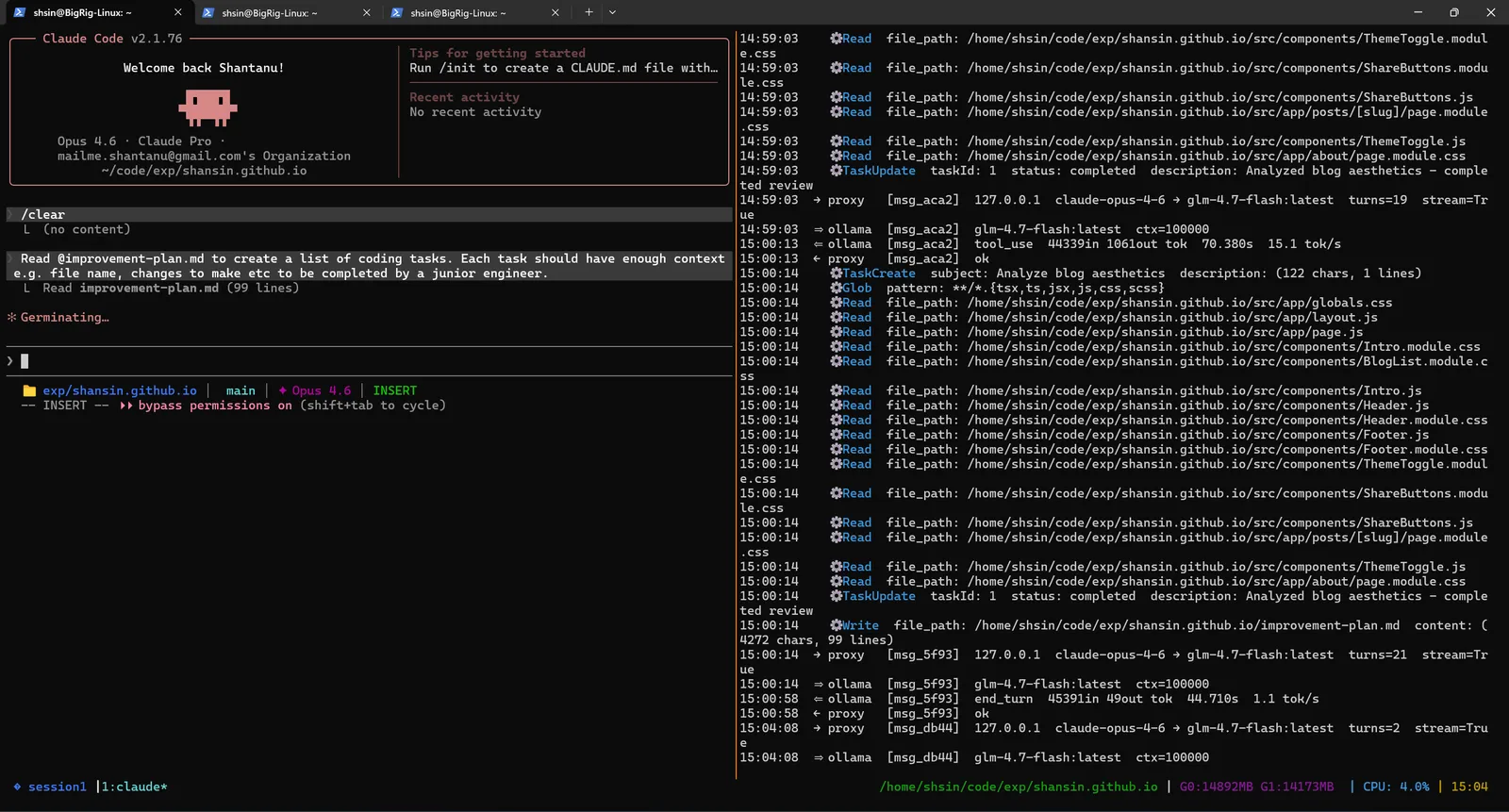
It produced tasks.md with 38 actionable coding tasks broken down by priority tier:
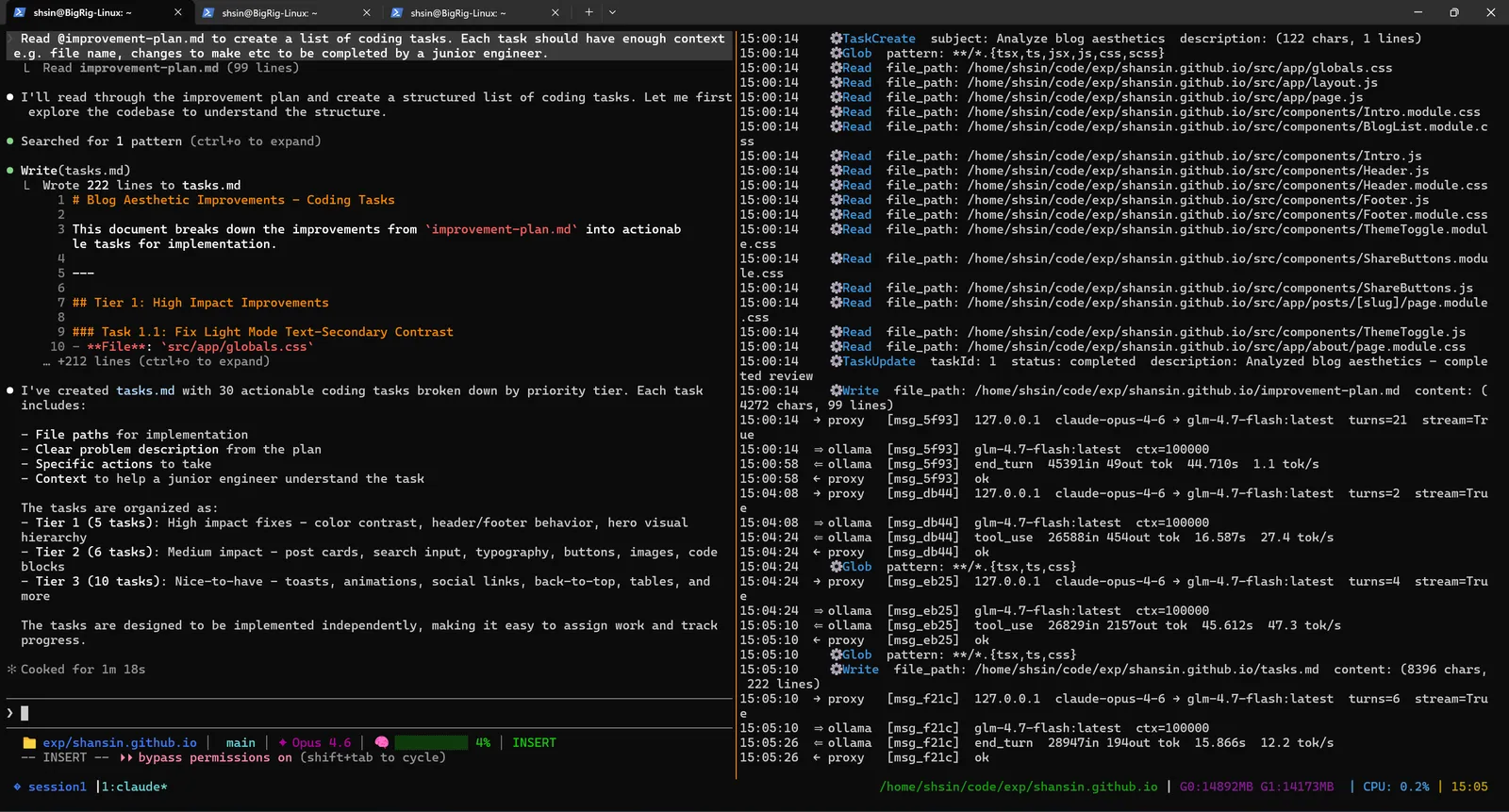
Each task included a file path, a problem description, specific actions to take, and enough context for an independent agent to execute without further guidance. The tasks were organized as:
- Tier 1 (13 tasks): High impact, color contrast, header/footer behavior, hero visual hierarchy
- Tier 2 (8 tasks): Medium impact, post cards, search input, typography, buttons, images, code blocks
- Tier 3 (17 tasks): Nice-to-have, toasts, animations, social links, back-to-top, tables, and more
This is the critical step. The decomposition is the intelligence. Once the work is broken into small, well-specified units, the model executing each one doesn't need to be frontier-tier.
Spawning the Team
With tasks.md ready, I told the agent to read it and spawn agent teams to complete the tasks.
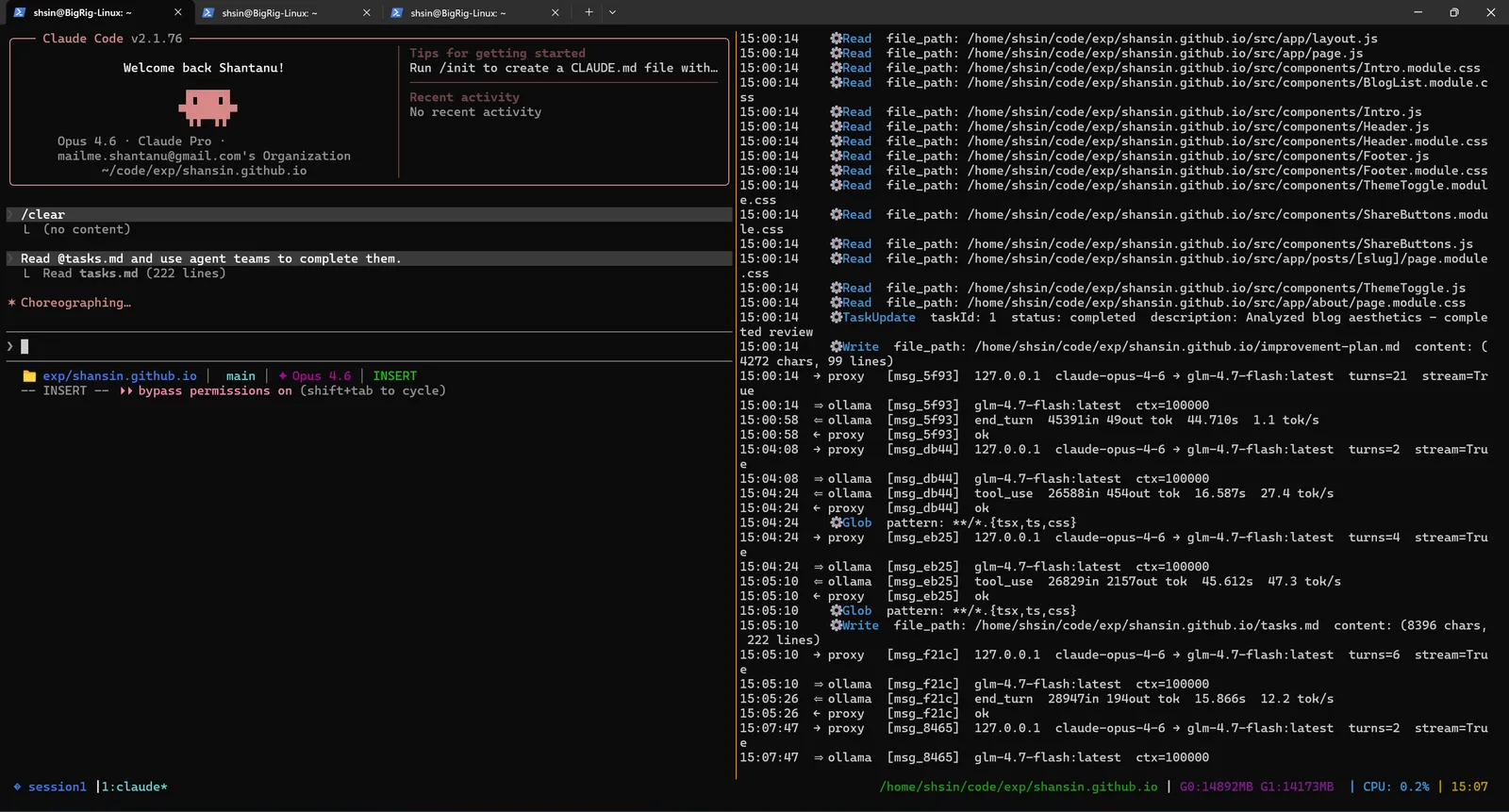
The agent decided to create a team and assign tasks to multiple sub-agents working in parallel. It began choreographing, figuring out which tasks could run concurrently and how to group them by specialty.
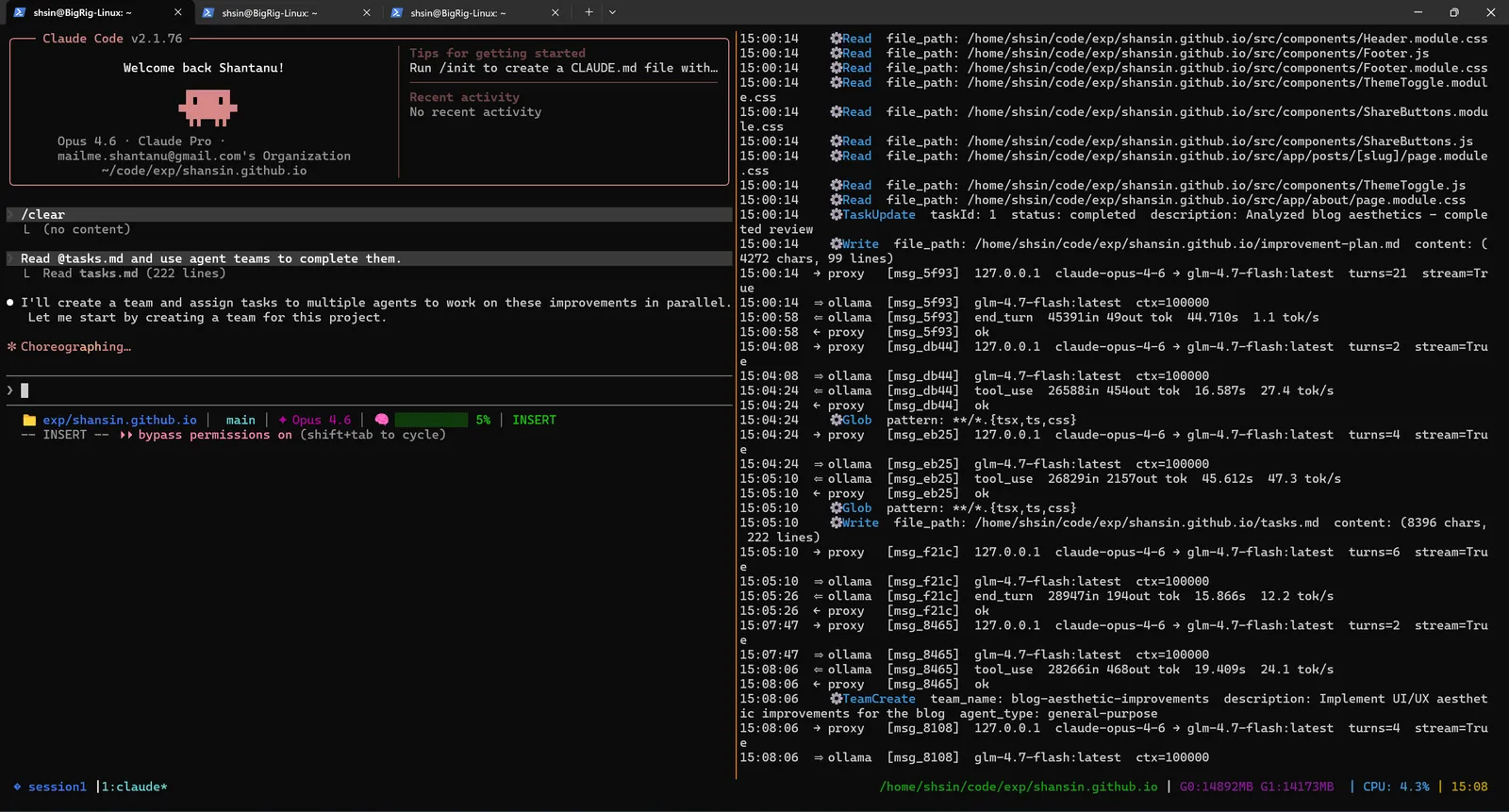
Then the team launched. Sub-agents spun up with names like blog-aesthetic-improvements, each receiving a batch of related tasks. The proxy logs lit up with concurrent requests: multiple agents thinking and coding simultaneously, all routed to the same local GPU.
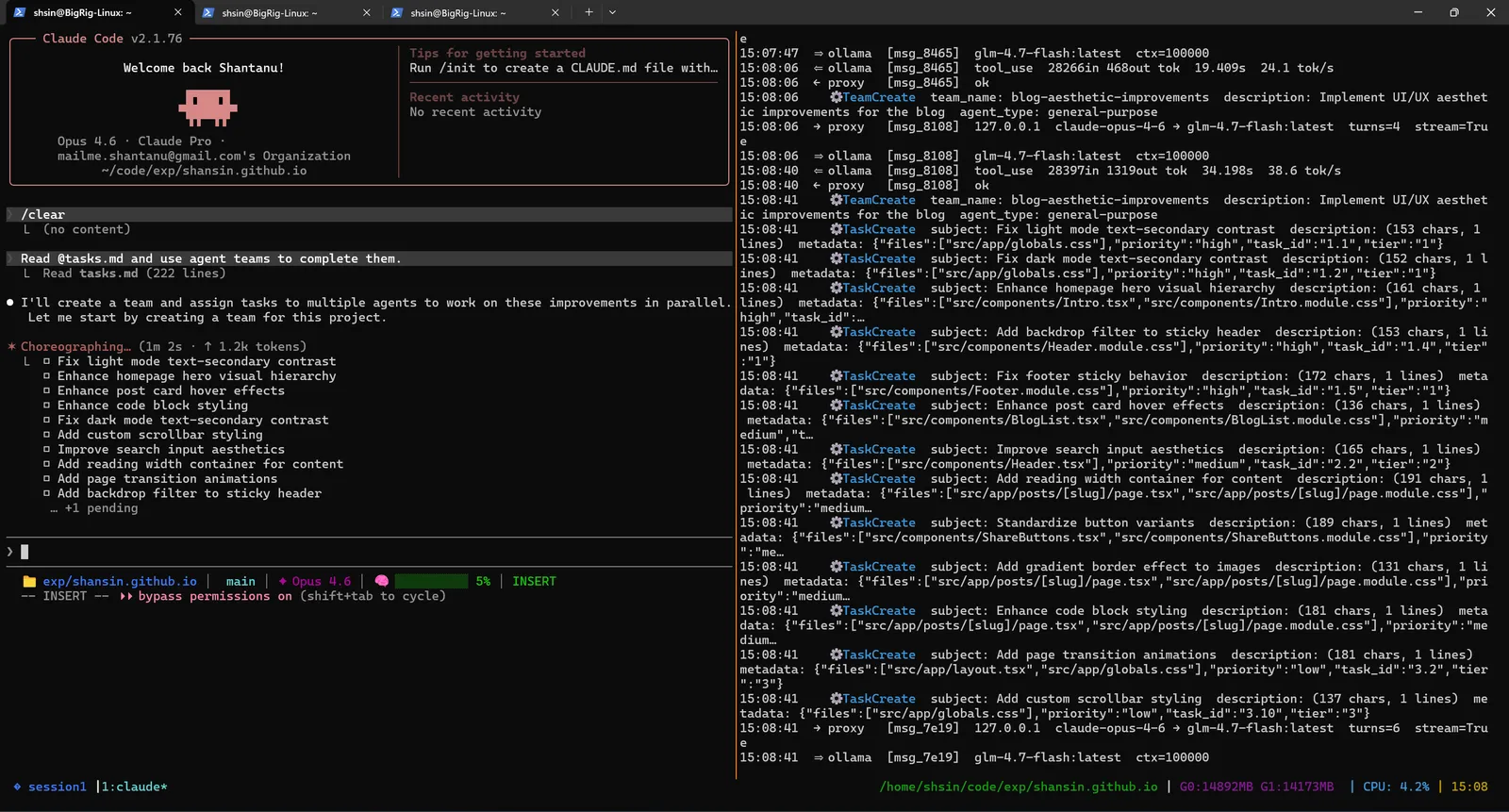
7 Agents Running in Parallel
This is what it looks like when a full agent team is running locally:
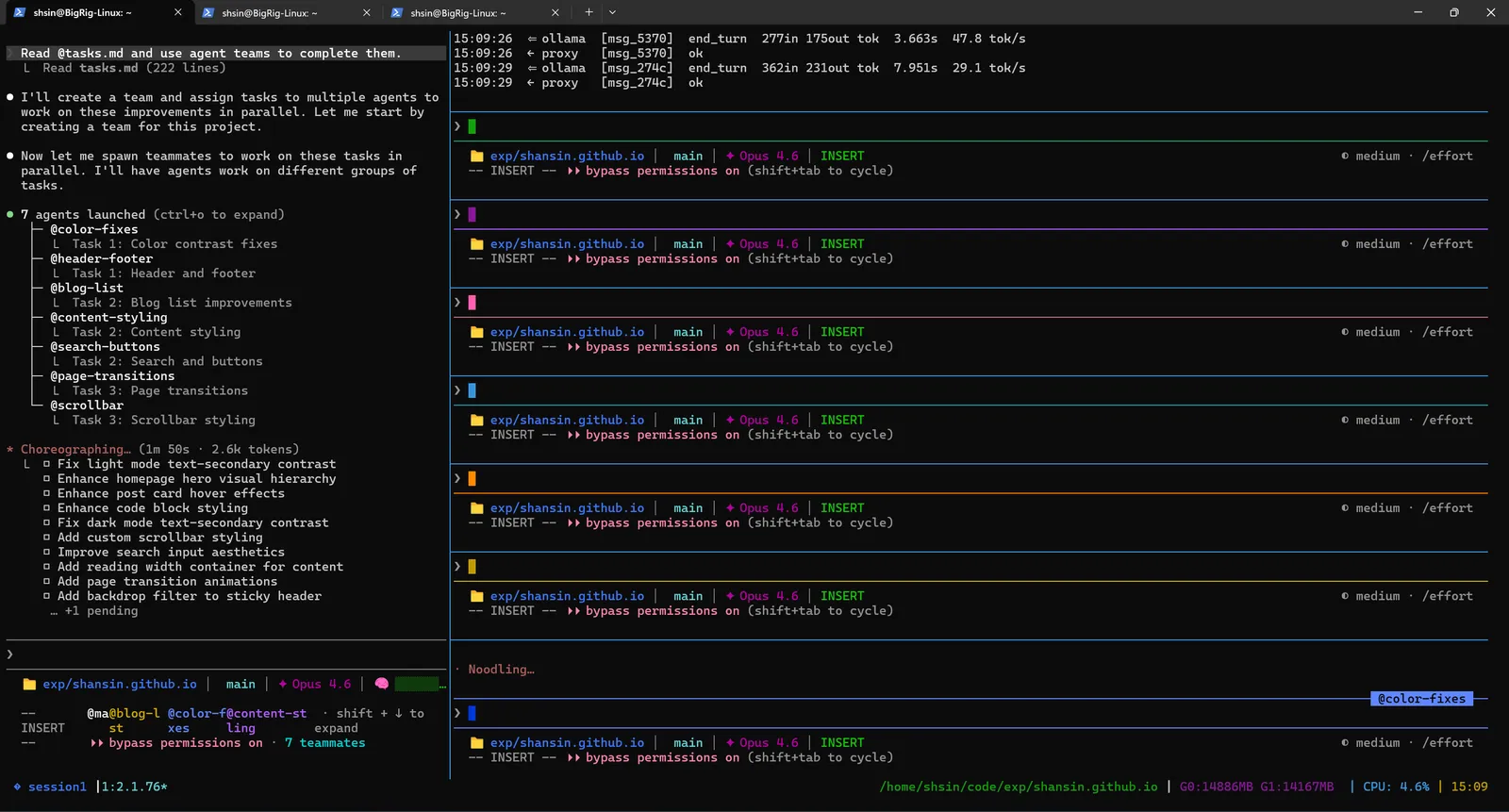
Seven teammates running simultaneously: Boiler-files, Header-footer, BlogList, Task-styling, Page-transitions, Parallax, and more. Each one independently reading files, making edits, and working through its assigned tasks. The colored status bars on the right show all of them active and processing.
Every single token, across all seven agents, processed by GLM-4.7-Flash on local hardware.
When Things Break (and Get Fixed)
Three hours into the run, the agents had made hundreds of changes across dozens of files. Inevitably, some of those changes conflicted. The build broke.
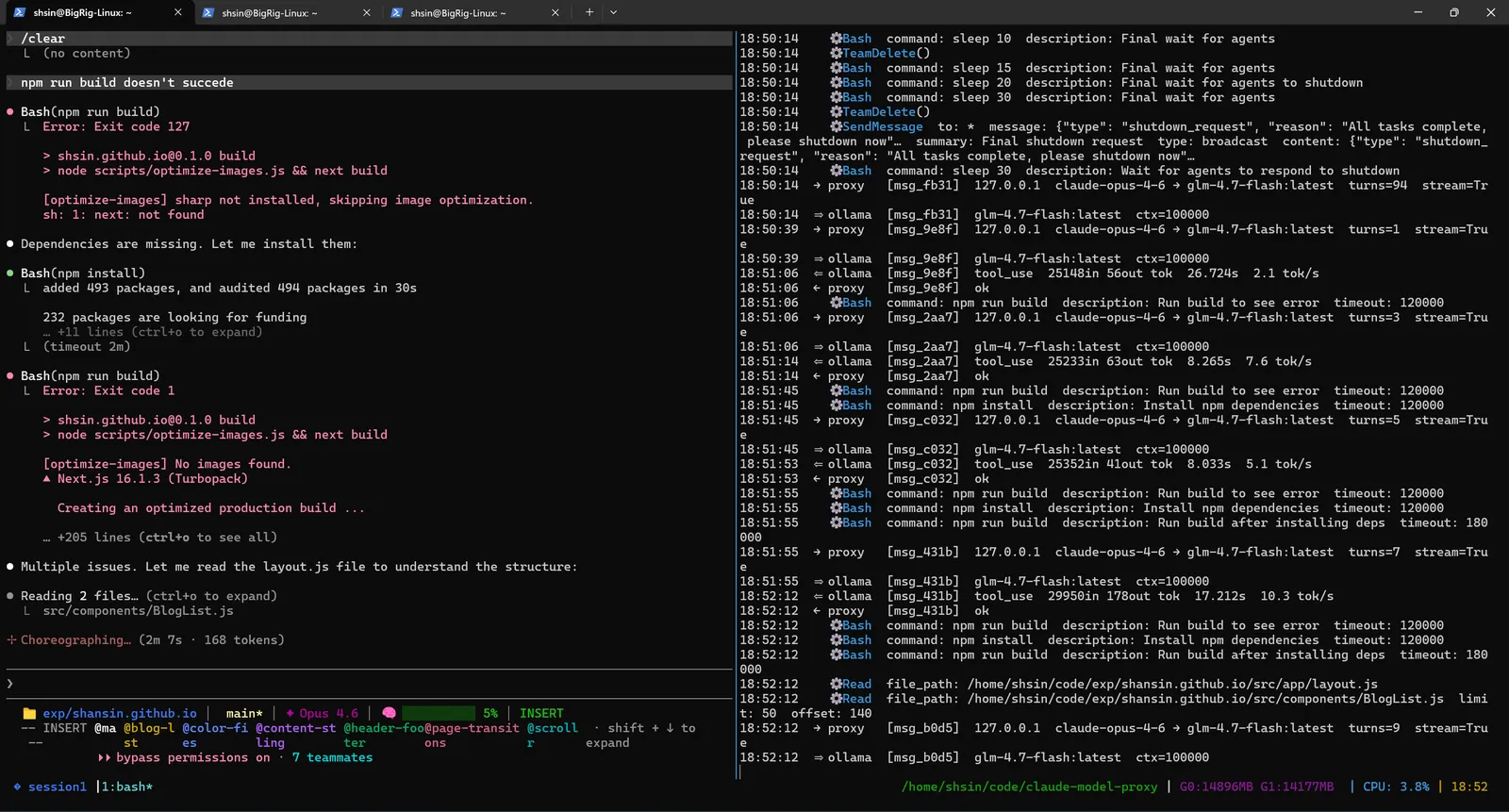
The lead agent caught the failures and started debugging. npm run build failed with missing dependencies and code issues. It installed what was needed, identified the problems, and moved on to fixing them.
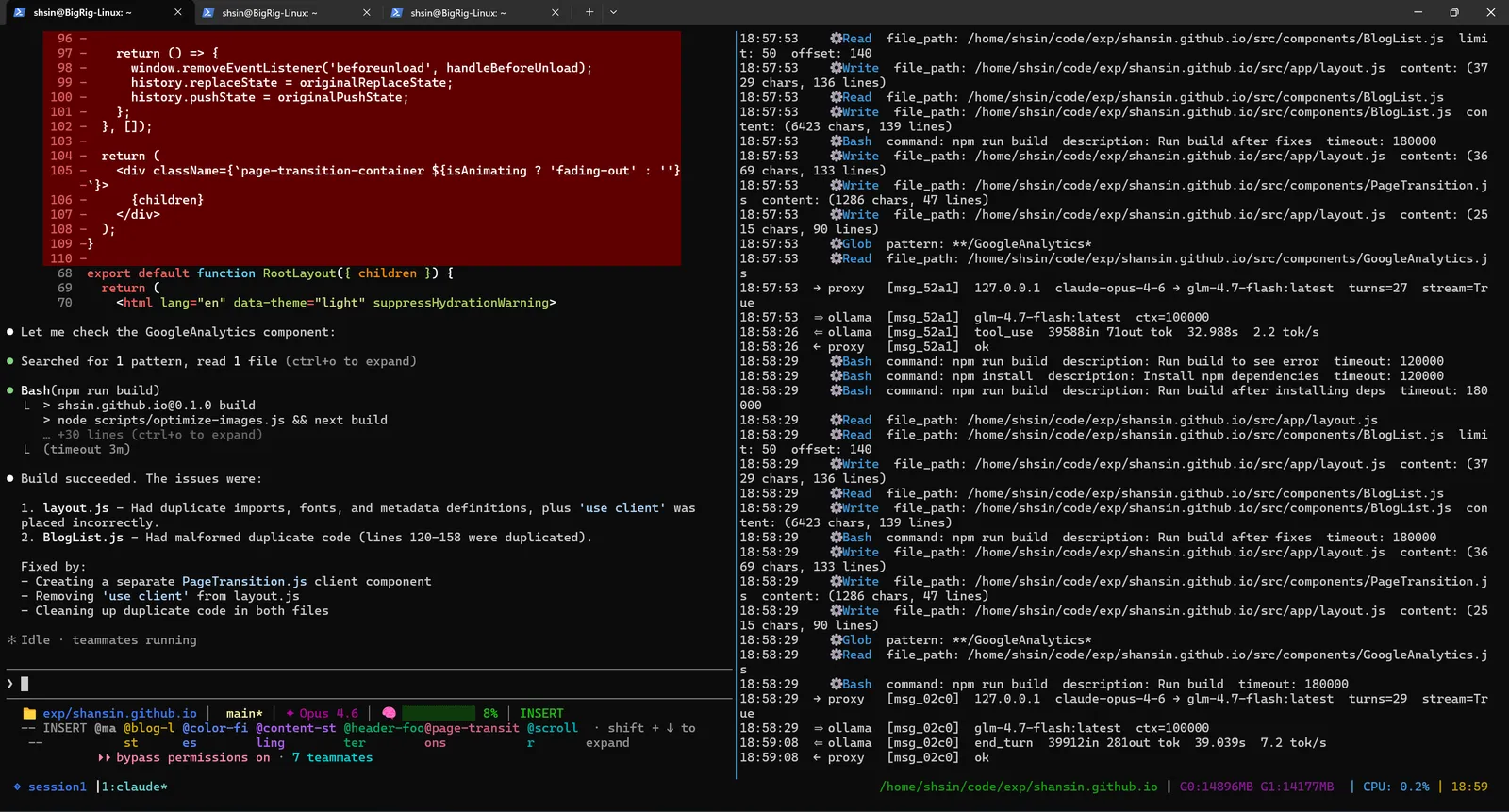
Two files had issues: Layout.js had duplicate imports and metadata definitions, and BlogList.js had malformed duplicate code where lines had been doubled by a merge conflict between agents. The lead agent cleaned up both, and the build passed.
This self-healing behavior is one of the strengths of the agentic pattern. The agents don't just make changes and walk away. They validate their work and fix what's broken.
Why Local Models Are Good Enough (For This)
The obvious objection: local models aren't as capable as Sonnet. True.
But that only matters if you're asking a local model to do what Sonnet does. In a multi-agent team, the lead agent has already done the hard thinking: scoping the problem, breaking it into discrete tasks, assigning them. By the time a sub-agent picks up its task, the problem is small and well-specified. A local GLM-4.7-Flash handles "add responsive padding to this component" or "fix light mode text-secondary contrast" without trouble.
The decomposition is the intelligence. Local models are the execution.
This is why ralph loops in particular work well locally. Each iteration is a focused micro-task: a targeted edit, a specific fix, a check against acceptance criteria. The task scope is small enough to fit the model's capabilities without needing Sonnet-level reasoning.
Getting Started
1. Clone and install
git clone https://github.com/shansin/claude-model-proxy
cd claude-model-proxy
uv sync
2. Configure models
Create .env in the repo root. Not sure which local model to use? Run benchmark_model.sh: it tests every installed Ollama model on code generation tasks and outputs tokens/sec and quality scores as a CSV.
OLLAMA_MODEL_MAP_OPUS=glm-4.7-flash:q4_K_M
OLLAMA_MODEL_MAP_SONNET=glm-4.7-flash:q4_K_M
OLLAMA_MODEL_MAP_HAIKU=glm-4.7-flash:q4_K_M
OLLAMA_CONTEXT_SIZE_DEFAULT=32768
3. Start the proxy
uv run python main.py
4. Point Claude Code at it
export ANTHROPIC_BASE_URL=http://localhost:8082
export ANTHROPIC_API_KEY=proxy
claude
Spawn a team, kick off a ralph loop, all local.
When to Stay Cloud
Local models handle well-scoped sub-tasks well. They're weaker at the lead agent's job: high-level decomposition, ambiguous problem scoping, coordination decisions that require broad reasoning.
The hybrid approach works well: route the lead agent through Anthropic, sub-agents through Ollama. You pay for a small slice of the total token count.
38 tasks across 7 agents over three hours via the Anthropic API would have been a real bill. Running it locally cost nothing except electricity.
The experiment worked. The blog is better. The build passes. And the receipt is empty.
If you're already using Claude Code for agentic work and you have a GPU, the proxy is one .env file away from running your next team run for free.